Debugging Spark Code Locally Like A Boss
Stepping through Spark internals can be helpful. If anything, it helps make sense of what your code is doing under the hood. In this post I'm going to explain how I setup my debugger to hit breakpoints within the Spark codebase to be able to debug Spark Scala, Java and Python code.
The Prep
Setting up Spark locally involves downloading Hadoop binaries and Spark source code. I will be using IntelliJ for this tutorial but in theory any IDE can let's you run and debug JVM based languages should do. This is being setup on a Macbook Pro but there's no reason this wouldn't work on Windows. I don't have access to a PC so some exploration might be needed on your part for that.
What you'll need
-You need Java 11 installed. Any LTS or version after 8 should do.
-Maven 3.6.3 or above installed.
-Scala 2.12.10 or above installed.
-Python 3 installed.
-Minimum 8 GB of RAM.
-Jetbrains IntelliJ IDE. I use the Ultimate version but this should work fine on the Community version.
-Coffee or drink of choice because you are going to need it.
The Setup
We're going to download and setup Hadoop and Spark. Following that we'll configure IntelliJ. The most time consuming phase will be the Spark compilation. Ironically the most frustrating phase could be the IntelliJ configuration.
Setup Hadoop
We'll need to install Hadoop binaries first. There's no reason you can't download the source and build it but that is unnecessary for what we're trying to achieve here.
Hadoop 3.2.1 is the version of binaries that will be used in this tutorial. As long as you're setting up a version of Hadoop that is compatible with the version of Spark you're using, we should be fine. The process hasn't changed much with versions.
Fetch the Hadoop binaries from: https://hadoop.apache.org/releases.html
Setting up is as simple as unzip the compressed file and placing them in a more permanent location on your hard drive. If you
have a Downloads folder where all your downloads go, you might want to unzip the hadoop file somewhere else.
Once that is done, add an entry to your .bash_profile or similar so that HADOOP_HOME is declared on startup.
export HADOOP_HOME=/Users/<YOUR USERNAME>/<Location of hadoop binaries>/Hadoop/hadoop-3.2.1/binTo check the environment variable points to the right place, type what's below at the command line if on a Mac or Linux variant.
env | grep HADOOP_HOME Setup Spark
We're going to git clone the Apache Spark repo and compile it locally.
Clone the Spark repo.
git clone https://github.com/apache/sparkChange into the directory and build Spark from source using the below commands. Run the maven build command without sudo so that IntelliJ does not give you problems when trying to build or read the target folder. Hang in there, the compilation might take a while depending on your specs.
cd spark
mvn -DskipTests clean packageAfter the build finishes, you can test out that Spark has build correctly by running one of the binaries in the bin folder.
bin/spark-shellYou should see something similar to the screenshot below.

If the Spark Scala shell opens up for you then you are done with this step.
Setting up IntelliJ
We're almost there. Fire up IntelliJ and open the recently compiled Spark directory in it. Indexing might take a while but you don't wait for it to finish to continue on with the remaining steps.
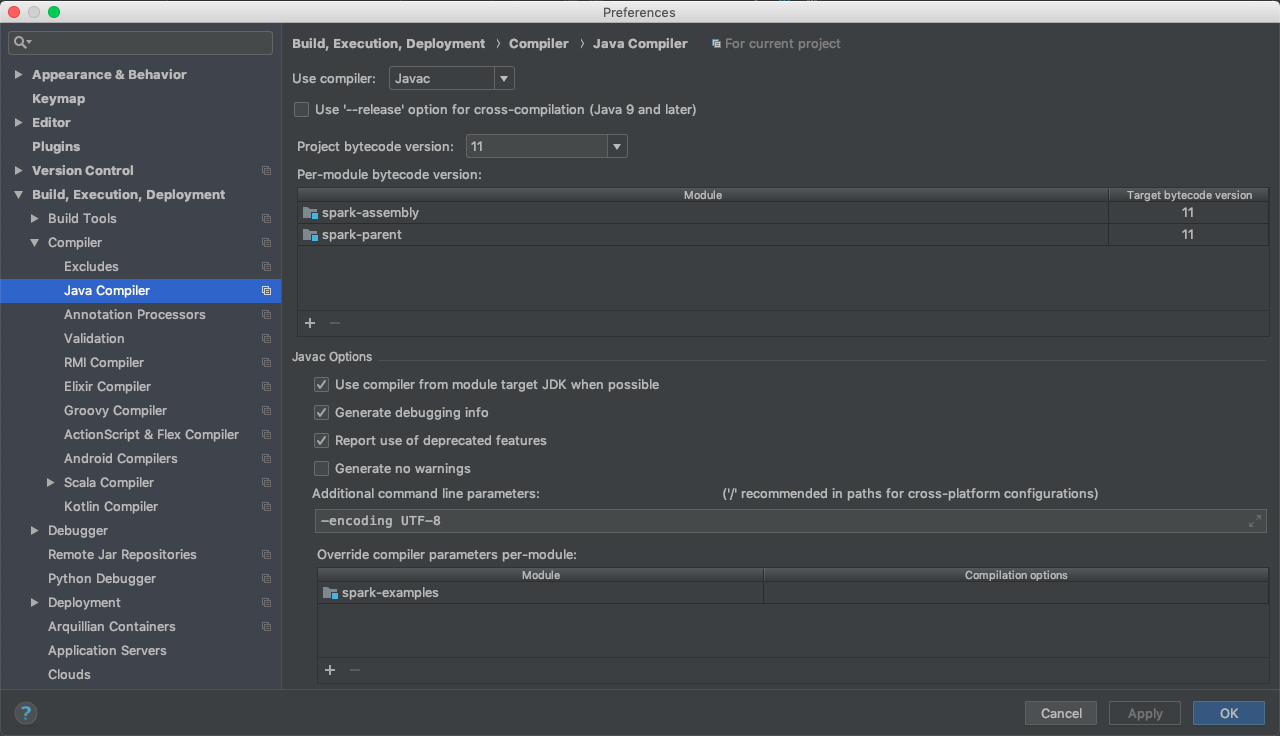
First we go to IntelliJ > Preferences > Build, Execution, Deployment > Compiler > Java Compiler Menu. You will need to set it up similar to the screenshot below.
The checkbox next to Use '--release' option for cross-compilation (Java 9 and later) should be unchecked.
Add spark-assembly and spark-parent to the per-module bytecode version section.
Add spark-examples under the override compiler parameters per-module section.
The indexing should have finished by now. If it hasn't, we have no choice but to wait before proceeding. Take a break. You've earned it.
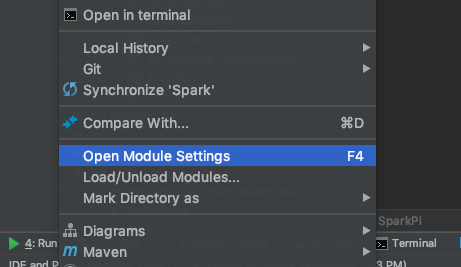
Left click on the Spark (spark-parent) directory in the Project tab and click on "Open Module Settings". You'll need to make sure all modules that are dependencies are detected correctly. If any of the examples have imports that can't be found, this should sort that situation out.
Once there you should be looking at something similar to what's below. If no modules are shown, use the + button to add them.
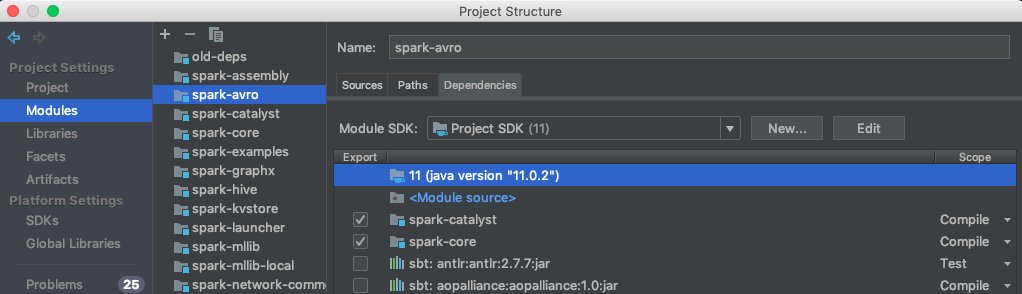
I'm going to list out the modules that need to be checked for particular spark modules. In the screenshot above you can see that spark-avro is selected and in the view that follows, spark-catalyst and spark-core are checked. You are going to have to do this for a bunch of modules. If a module isn't on the list, simply add it using the + button.
Modules and their dependencies
spark-avro depends on spark-catalyst, spark-core, spark-sql and spark-tags
spark-catalyst depends on spark-core, spark-sketch, spark-tags and spark-unsafe
spark-core depends on spark-kvstore, spark-launcher, spark-network-common, spark-network-shuffle,
spark-tags and spark-unsafe
spark-examples depends on spark-sql
spark-graphx depends on spark-core, spark-mllib-local and spark-tags
spark-hive depends on spark-catalyst, spark-core, spark-sql and spark-tags
spark-kvstore depends on spark-tags
spark-launcher depends on spark-tags
spark-mllib depends on spark-catalyst, spark-core, spark-graphx, spark-mllib-local, spark-sql,
spark-streaming, spark-tags
spark-mllib-local depends on spark-tags
spark-network-common depends on spark-tags
spark-network-shuffle depends on spark-tags, spark-network-common
spark-repl depends on spark-tags, spark-core, spark-mllib and spark-sql
spark-sketch depends on spark-tags
spark-sql depends on spark-catalyst, spark-core, spark-sketch and spark-tags
spark-sql-kafka-0-10 depends on spark-tags, spark-catalyst, spark-core, spark-sql,
spark-token-provider-kafka-0-10
spark-streaming depends on spark-core, spark-tags
spark-streaming-kafka-0-10 depends on spark-tags, spark-core, spark-streaming, spark-token-provider-kafka-0-10
spark-streaming-kafka-0-10-assembly depends on spark-streaming, spark-streaming-kafka-0-10
spark-token-provider-kafka-0-10 depends on spark-tags, spark-core
spark-unsafe depends on spark-tagsWhew! That was a long list. Congratulations on making it this far. Next we're going to setup one example each for debugging. A Java example, a Scala example and a Python example. The spark-examples folder contains examples in all supported programming languages.
The Java Example
We're going to set up the JavaSparkPi example so that it's debuggable. You can follow this process for any of the java examples.
Go to Run > Edit Configurations.
On the screen that follows, click the + button and choose Application. Fill out the fields similar to the screenshot below.
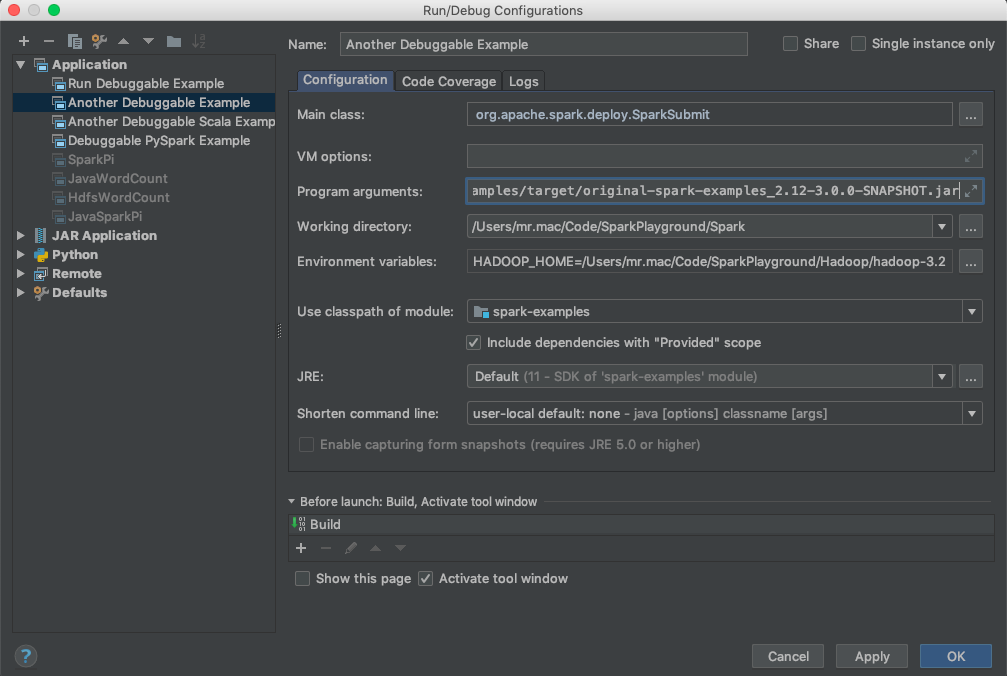
For Environment variables, copy paste what's below.
--class
org.apache.spark.examples.JavaSparkPi
--master
local
examples/target/original-spark-examples_2.12-3.0.0-SNAPSHOT.jarThe Scala Example
For Scala we're going to use the SparkPi example.
Similar to above, go to Run > Edit Configurations.
On the screen that follows, click the + button and choose Application. Fill out the fields similar to the screenshot below.
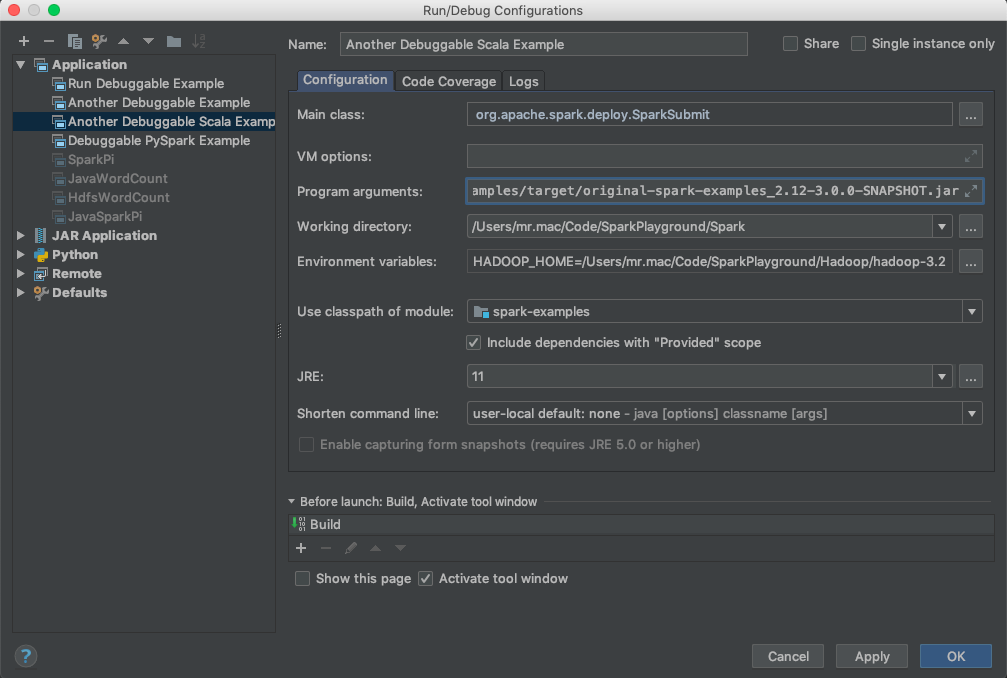
For Environment variables, copy paste what's below.
--class
org.apache.spark.examples.SparkPi
--master
local
examples/target/original-spark-examples_2.12-3.0.0-SNAPSHOT.jarThe Python Example
For Python we're going to be using the logistic_regression example.
Once again, go to Run > Edit Configurations.
On the screen that follows, click the + button and choose Application. Fill out the fields similar to the screenshot below.
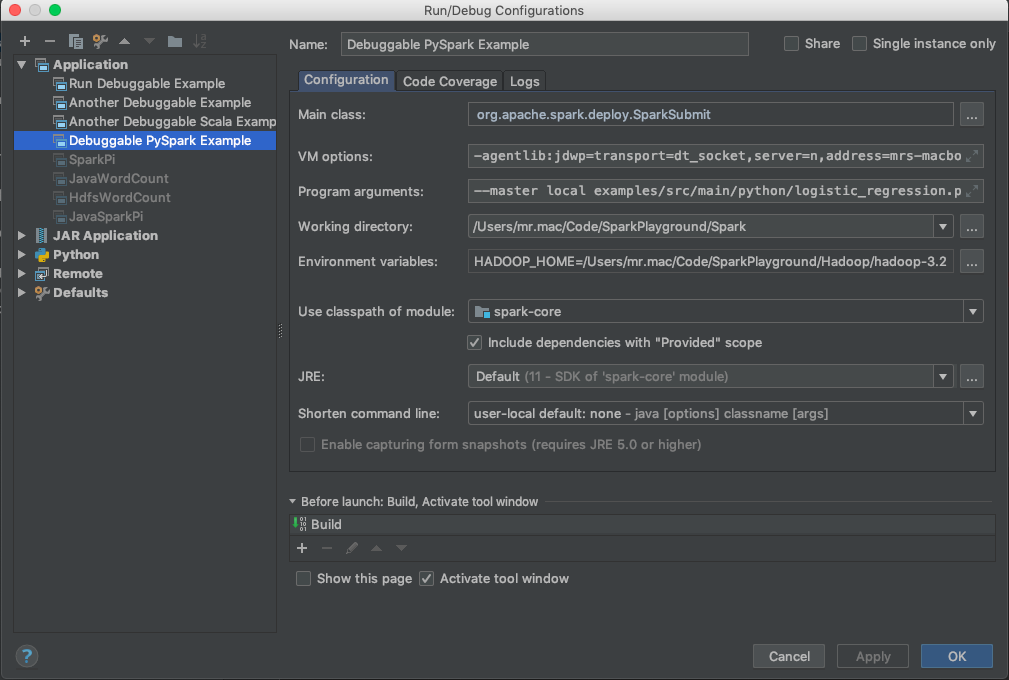
For the VM options field, use what's below. Substitute
-agentlib:jdwp=transport=dt_socket,server=n,address=<Your host name>:8086,suspend=y,onthrow=org.apache.spark.SparkException,onuncaught=nIn the program arguments field, use what's below.
--master
local
examples/src/main/python/logistic_regression.pyYou should be set.
Steps to Debug
Set a breakpoint in any example you have set up.
You should a dropdown similar to what's below. Click on the bug icon to debug.

You should now be greeted with this when your breakpoint is hit.
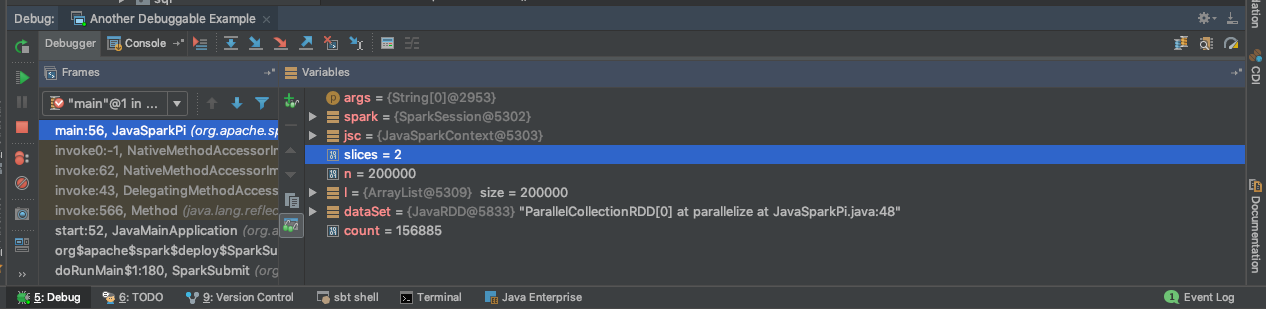
Congratulations! You're now debugging Spark code on local like a Boss!